Unified database for Language Models: LMSpecs
LMSpecs is a language model with a database of 3+ integrated benchmarks/scores, providing a versatile framework to evaluate its language understanding, generation, and reasoning across diverse tasks, aiding researchers in optimizing it for real-world use.

Isn't it tough for models to gather information?
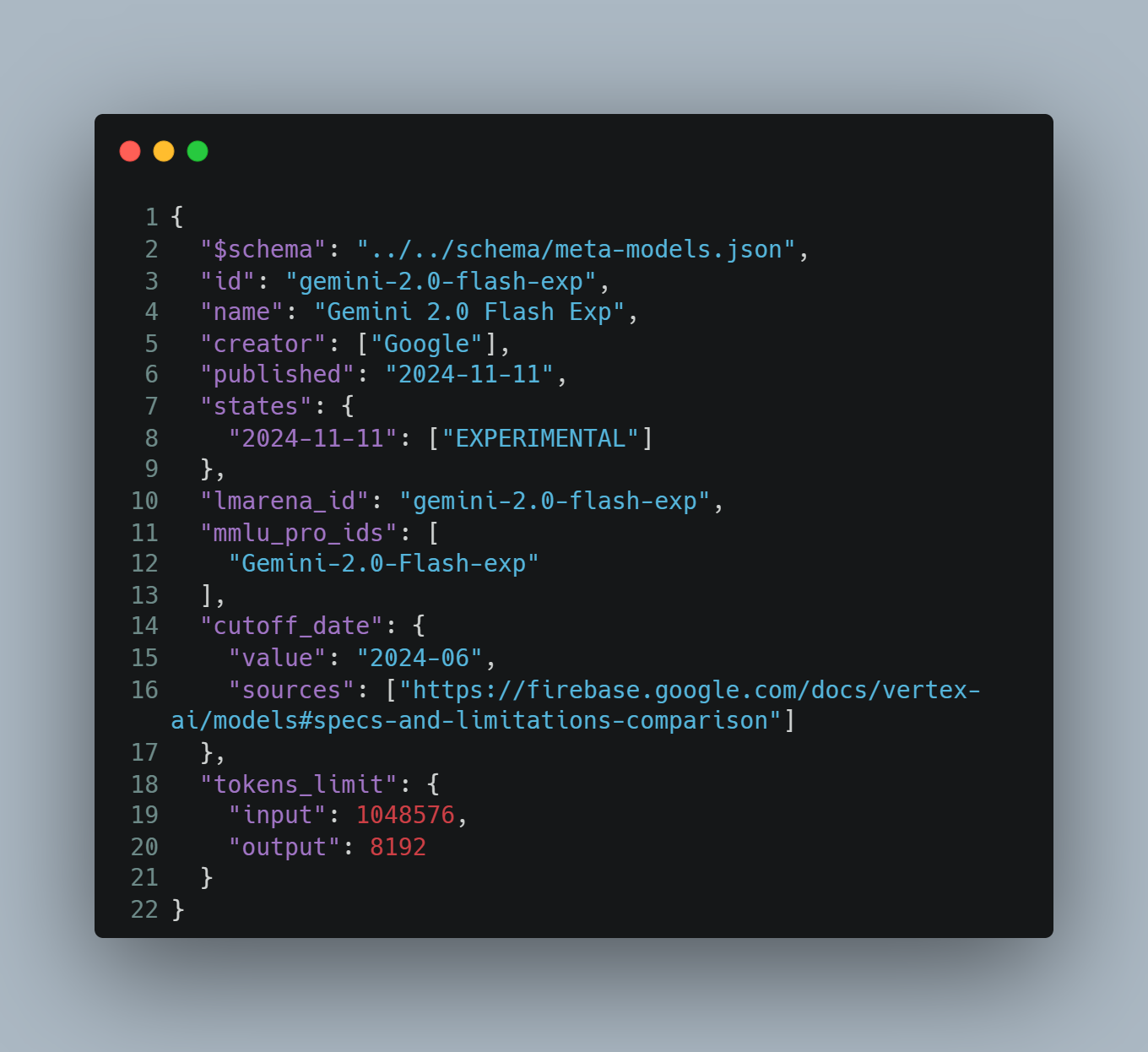
Gathering information about language models can be challenging because the details are often scattered across a developer's website. For instance, when trying to find out about a model's knowledge cutoff, you might not find it in the official documentation, but it could be tucked away in a blog post from the release date. This fragmentation makes it tough to get a complete picture of an LLM. However, with LMSpecs, all of this information can be comprehensively understood in one place.
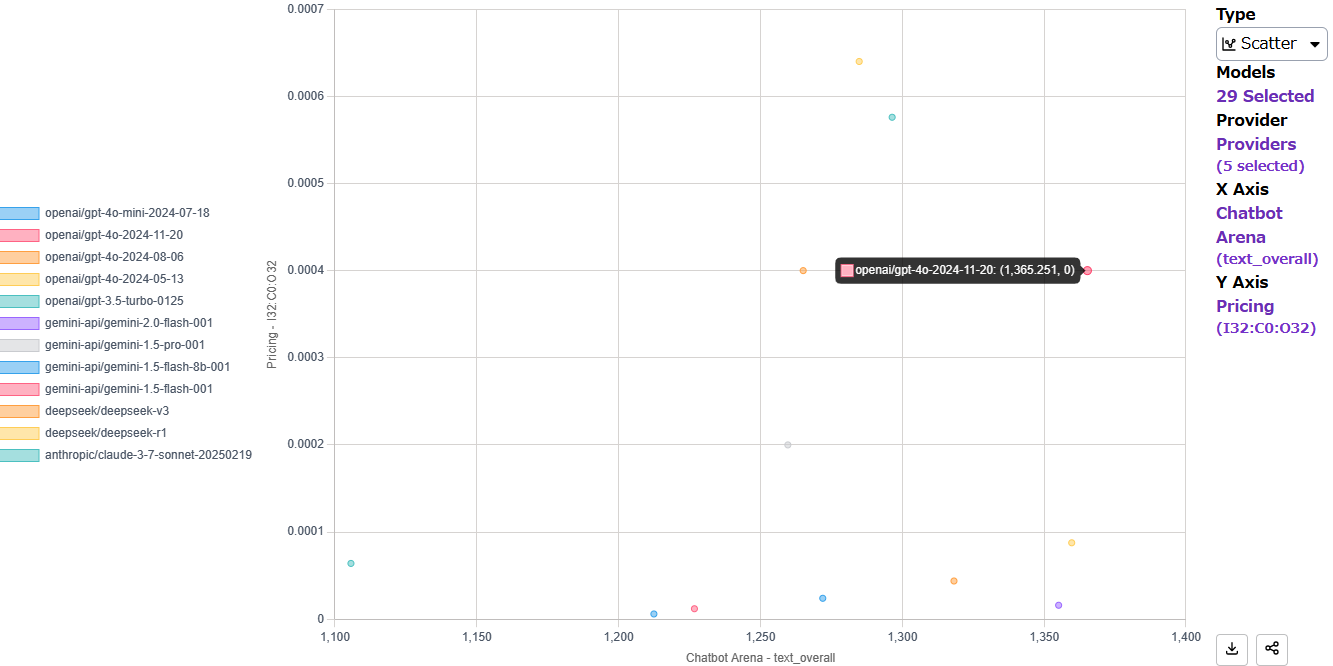
Can a Single Score Define a Model’s Worth?
When evaluating language models, relying on just one score might not tell the whole story. Instead, using a variety of benchmarks—alongside factors like cost, speed, and other performance metrics—allows for a more comprehensive, multi-dimensional assessment. This approach makes it easier to identify the model that best fits your specific product needs.